DI-V2X: Learning Domain-Invariant Representation for Vehicle-Infrastructure Collaborative 3D Object Detection
Abstract
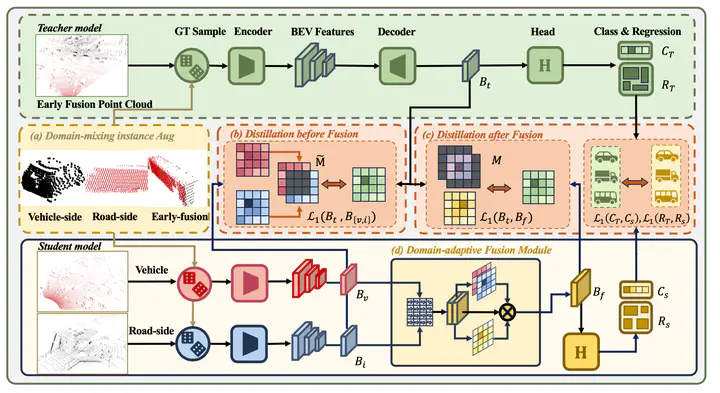
Vehicle-to-Everything (V2X) collaborative perception has recently gained significant attention due to its capability to enhance scene understanding by integrating information from various agents, e.g., vehicles, and infrastructure. However, current works often treat the information from each agent equally, ignoring the inherent domain gap caused by the utilization of different LiDAR sensors of each agent, thus leading to suboptimal performance. In this paper, we propose DI-V2X, that aims to learn Domain-Invariant representations through a new distillation framework to mitigate the domain discrepancy in the context of V2X 3D object detection. DI-V2X comprises three essential components, a domainmixing instance augmentation (DMA) module, a progressive domain-invariant distillation (PDD) module, and a domainadaptive fusion (DAF) module. Specifically, DMA builds a domain-mixing 3D instance bank for the teacher and student models during training, resulting in aligned data representation. Next, PDD encourages the student models from different domains to gradually learn a domain-invariant feature representation towards the teacher, where the overlapping regions between agents are employed as guidance to facilitate the distillation process. Furthermore, DAF closes the domain gap between the students by incorporating calibrationaware domain-adaptive attention. Extensive experiments on the challenging DAIR-V2X and V2XSet benchmark datasets demonstrate DI-V2X achieves remarkable performance, outperforming all the previous V2X models.