Junbo Yin
Junbo Yin
Home
News
Publications
Activities
Light
Dark
Automatic
1
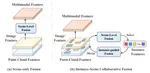
IS-FUSION: Instance-Scene Collaborative Fusion for Multimodal 3D Object Detection
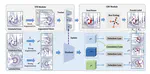
A novel multimodal 3D object detection algorithm, IS-Fusion, is presented in this work. It enhances the previous multimodal BEV representation by incorporating instance-level information, which significantly improves detection performance. IS-Fusion achieves the best performance among the published works to date.
Junbo Yin
,
Jianbing Shen
,
Runnan Chen
,
Wei Li
,
Ruigang Yan
,
Pascal Frossard
,
Wenguan Wang
PDF
Cite
Code
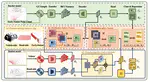
DI-V2X: Learning Domain-Invariant Representation for Vehicle-Infrastructure Collaborative 3D Object Detection
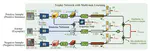
We propose a new collaborative 3D object detection algorithm (DI-V2X) aimed at minimizing the domain discrepancy of the input data from various sources, including vehicles and infrastructure. Our approach features three key modules, the Domain-Mixing Instance Augmentation (DMA) module, the Progressive Domain-Invariant Distillation (PDD) module, and the Domain-Adaptive Fusion (DAF) module. DI-V2X achieves the best performance in V2X perception.
Xiang Li
,
Junbo Yin
,
Wei Li
,
Chengzhong Xu
,
Ruigang Yang
,
Jianbing Shen
PDF
Cite
Code
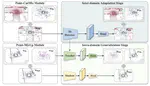
LWSIS: LiDAR-Guided Weakly Supervised Instance Segmentation for Autonomous Driving
We present a novel learning paradigm, LWSIS, that inherits the fruits of off-the-shelf 3D point cloud to guide the training of 2D instance segmentation models to save mask-level annotations. We advocate a new dataset nuInsSeg based on nuScenes to extend existing 3D LiDAR annotations with 2D image segmentation annotations.
Xiang Li
,
Junbo Yin
,
Botian Shi
,
Yikang Li
,
Ruigang Yang
,
Jianbing Shen
PDF
Cite
Code
Dataset
SSDA3D: Semi-supervised Domain Adaptation for 3D Object Detection from Point Cloud
We prsent SSDA3D in this work, which is the first effort for semi-supervised domain adaptation in the context of 3D object detection. SSDA3D is achieved by a novel framework that jointly addresses inter-domain adaptation and intra-domain generalization.
Yan Wang
,
Junbo Yin
,
Wei Li
,
Pascal Frossard
,
Ruigang Yang
,
Jianbing Shen
PDF
Cite
Code
ProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
We propose a proposal-level point cloud SSL framework, named ProposalContrast, that conducts proposal-wise contrastive pre-training for detection-aligned representation learning. We comprehensively demonstrate the generalizability of our model across diverse 3D detector architectures and datasets.
Junbo Yin
,
Dingfu Zhou
,
Liangjun Zhang
,
Jin Fang
,
Cheng-Zhong Xu
,
Jianbing Shen
,
Wenguan Wang
PDF
Cite
Code
Semi-supervised 3D Object Detection wit Proficient Teachers
We propose ProficientTeachers for LiDAR-based 3D object detection, which is achieved by promoting the plain teacher model to proficient teachers inspired by ensemble learning. Our framework not only performs better results, but also removes the necessity of confidencebased thresholds for filtering pseudo labels.
Junbo Yin
,
Jin Fang
,
Dingfu Zhou
,
Liangjun Zhang
,
Cheng-Zhong Xu
,
Jianbing Shen
,
Wenguan Wang
PDF
Cite
A Unified Object Motion and Affinity Model for Online Multi-Object Tracking
We integrates singl object tracking and metric learning into a unified triplet network via multi-task learning. A task-specific attention module is also presented to address th specific nature of each task. Experimental results show that it achieves promising performance on several MOT benchmarks.
Junbo Yin
,
Wenguan Wang
,
Qinghao Meng
,
Ruigang Yang
,
Jianbing Shen
PDF
Cite
Code
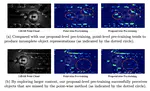
LiDAR-based Online 3D Video Object Detection with Graph-based Message Passing and Spatiotemporal Transformer Attention
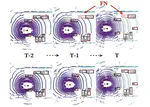
We propose a new LiDAR-based 3D video object detector that leverages the previous long-term information to improve the 3D detection performance. Extensive evaluations demonstrate that our 3D video object detector achieves better performance against the single-frame detectors.
Junbo Yin
,
Jianbing Shen
,
Chenye Guan
,
Dingfu Zhou
,
Ruigang Yan
PDF
Cite
An example conference paper
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis posuere tellus ac convallis placerat. Proin tincidunt magna sed ex sollicitudin condimentum.
Junbo Yin 阴俊博
,
Robert Ford
Jul 1, 2013
PDF
Cite
Code
Dataset
Project
Slides
Video
Source Document
Cite
×